Product
Solutions


DRY in GraphQL: How the Type Similarity Linting Rule Keeps Your Schema Clean

When working with big GraphQL schemas or large federated schemas with hundreds of subgraphs, it’s easy to overlook redundant or overly similar types, especially as your schema grows in complexity. This often happens when multiple teams contribute to the schema, leading to duplicate efforts and inconsistencies. Such redundancies violate the DRY (Don’t Repeat Yourself) principle—a best practice aimed at reducing repetition and ensuring every piece of information is represented clearly and uniquely.
Redundant types can lead to customer confusion, increased maintenance burdens, and higher chances of errors. To address this, we built the Type Similarity Linting Rule to proactively identify and prevent such issues, helping developers maintain clean, scalable GraphQL schemas.
The Challenge: Identifying Similar Types
GraphQL schemas can evolve rapidly in modern development workflows, especially when multiple teams are involved. Contributors might independently create types that serve similar purposes without realizing it. Consider these hypothetical types:
type UserProfile {
id: ID!
name: String!
email: String!
}
type AccountDetails {
userId: ID!
username: String!
emailAddress: String!
}
At first glance, these two types look different due to their field names, but they are conceptually very similar. Identifying such cases manually can be time-consuming and error-prone, especially for platform teams managing schemas on behalf of backend engineers.
The Solution: Type Similarity Linting Rule
Our linting rule automates the detection of redundant or similar types as part of CI/CD, empowering teams to enforce schema cleanliness without added manual effort. Here’s how it works:
1. Encoding GraphQL Types into Vectors
We encode each GraphQL type into a numerical vector representation, capturing key structural and semantic information such as field names, types, and relationships. Using a Bag of Words (BoW) approach, we treat fields and their associated types as “words,” simplifying the schema into a frequency-based representation. This ensures essential similarities are preserved while ignoring minor differences like field order or naming.
2. Computing Similarity with Cosine Similarity
Using these vectors, we calculate the cosine similarity between a newly added type and existing types in the schema. Cosine similarity measures the angle between vectors in multidimensional space, providing a score between 0 (completely dissimilar) and 1 (identical). This technique is common in AI and machine learning and allows us to detect semantic overlaps efficiently.
3. Scoring and Presenting Results
If the similarity score exceeds a defined threshold (e.g., 70%), the rule flags the new type and presents the top three most similar existing types. For example:
Warning: The new type AccountDetails is 85% similar to UserProfile. Consider reusing or extending the existing type instead of creating a new one.
4. Empowering Developers
This rule doesn’t enforce changes but provides actionable insights. Teams can:
- Refactor the new type to reuse or extend an existing one.
- Keep the new type with clear justification for its uniqueness.
5. Seamless Integration with GitHub Actions
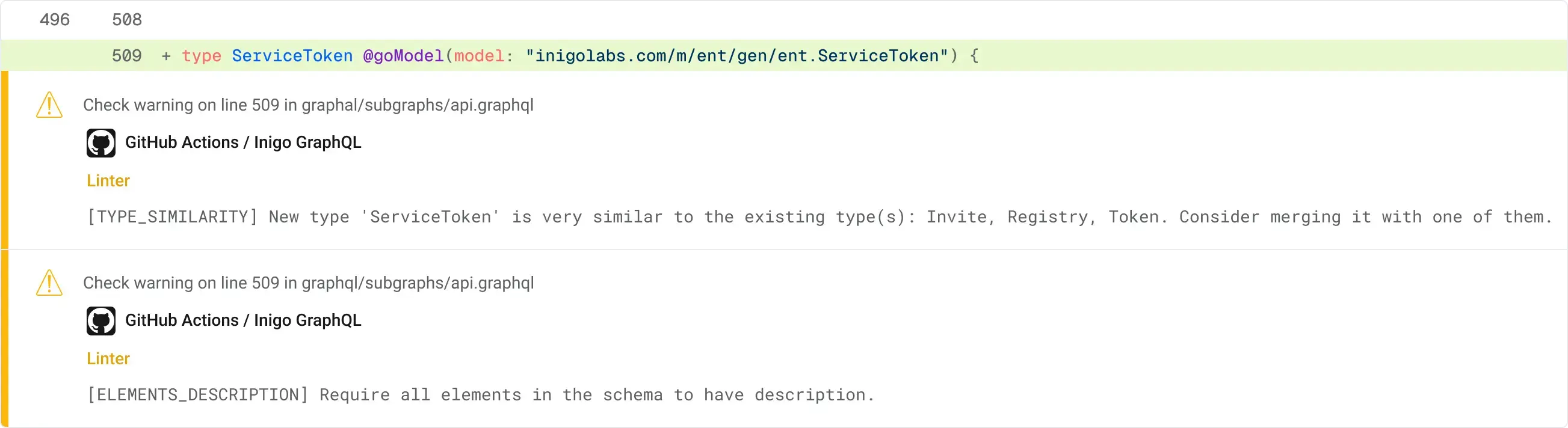 The linting rule integrates directly into GitHub Actions. When a developer opens a pull request , the action automatically analyzes the proposed changes and provides feedback. This ensures potential issues are flagged early in the development lifecycle, improving collaboration and reducing back-and-forth.
The linting rule integrates directly into GitHub Actions. When a developer opens a pull request , the action automatically analyzes the proposed changes and provides feedback. This ensures potential issues are flagged early in the development lifecycle, improving collaboration and reducing back-and-forth.
Why This Matters for Platform/API Teams
For platform and API teams, managing schemas for backend engineers, this tool significantly boosts efficiency by automating redundant type detection. It reduces schema conflicts during collaboration, enabling backend engineers to focus on delivering features instead of troubleshooting schema inconsistencies.
Reducing CFR and Troubleshooting Time
The Type Similarity Linting Rule helps reduce the Change Failure Rate (CFR) by identifying potential issues before they reach production. By flagging redundancies early, teams save valuable time during troubleshooting and ensure smoother deployments. This proactive approach supports a stable and efficient API development process.
Try It Out!
While integrating in CI/CD might take time, there’s a way to try it out on your schema directly from your terminal—no account needed.
Install the Inigo CLI:
brew tap inigolabs/homebrew-tap
brew install inigo_cli
Run it over your full schema:
inigo similar schema.graphql
To check a specific type:
inigo similar schema.graphql –threshold 0.7 –top 100 –target MyType
This quick setup allows you to see the Type Similarity Linting Rule in action and get instant insights into your schema’s structure.
Conclusion
The Type Similarity Linting Rule is a practical implementation of the DRY principle for GraphQL schemas. By leveraging vector encoding and cosine similarity, it automates the detection of redundant types, helping teams maintain clean and efficient schemas. Incorporating this rule into your development workflow can save time, reduce CFR, improve schema quality, and enhance collaboration across teams.