Product
Solutions


GraphQL in development

Overview
As applications evolve over time, it's essential for their GraphQL APIs to keep pace with these changes. In this blog post, we provide best practices for different aspects of the GraphQL development pipeline, including schema planning, schema checks, and performance optimization.
Managing schemas
GraphQL was built on the principle that each client should only retrieve the data it requires, effectively addressing the over-fetching issue. This approach anticipates that your API will be consumed by a wide range of clients, so that existing client queries should continue to function properly even as you expand and update your graph. It’s therefore important to determine which changes are permissible and which might break your schema.
Handling schema-breaking changes
A schema-breaking in a GraphQL schema is an update that causes the API contract to change in a way that is not backward-compatible. To better understand this concept, let's consider an example. Imagine you have a simple schema with a single query to fetch a user by ID, which returns a user type containing two fields: id and name. Your business then decides that they want to split the name field into two separate fields: firstName and lastName. You might be tempted to remove the name field and replace it with firstName and lastName, but doing so would break any existing clients relying on the name field.
# Original schema
type User {
id: ID!
name: String!
}
# Breaking change schema
type User {
id: ID!
firstName: String!
lastName: String!
}
Instead, you can make this change in a backward-compatible manner by using the @deprecated directive. This allows you to indicate that the name field is deprecated in favor of the new firstName and lastName fields.
# Backward-compatible schema
type User {
id: ID!
name: String! @deprecated(reason: "Use firstName and lastName instead")
firstName: String!
lastName: String!
}
When you need to introduce schema-breaking changes, follow these four steps to minimize their impact: add, deprecate, migrate, and remove.

In our example, we already added the new fields and deprecated the old one. Now, let's go through the remaining steps:
- Migrate: At this stage, it's crucial to update all the clients consuming this API to stop using the deprecated fields and start using the newly added fields. Once this migration is complete, deploy the updated versions of your website and applications.
- Remove: Once you're confident that there are no more clients that are using the deprecated fields anymore, you can safely remove them from the schema. In our example, you would remove the name field from the User type and deploy the new version of the API.
How can you be confident that no clients are using the deprecated fields anymore? This is where Inigo’s GraphQL Gateway can help. Inigo highlights the usage of each GraphQL object and tags them by client so you get visibility to your APIs usage in depth. By providing insights into usage patterns and real traffic data, developers using Inigo are empowered to plan their schema roadmaps effectively.
Schema checks
While the example shown above assumes that the developer already knows that adding firstName and lastName can potentially break the schema, in other cases, it’s not so clear. This is where GraphQL schema checks can be helpful. GraphQL schema checks help developers identify and prevent breaking changes in the schema, such as field removals or type modifications.
Schema checks for GraphQL are typically implemented by using tools and libraries designed for this purpose, and then integrating them into your development workflow and CI/CD pipeline. Here's an overview of the process:
- Choose a tool or library for schema checking: there are several popular tools for GraphQL schema checks, such as GraphQL Inspector, Apollo Engine, or Inigo. These tools can compare the current schema with the proposed changes and report any breaking changes or potential issues.
- Implement schema checks in development: during development, use the tool you chose to validate schema changes locally, ensuring that breaking changes are detected early in the development process. Developers can also use these tools to validate queries and mutations against the schema to guarantee their correctness.
- Integrate schema checks into your CI/CD pipeline: add schema checks to your continuous integration (CI) and continuous deployment (CD) pipelines. This can be done using plugins, scripts, or pre-built integrations with popular CI/CD platforms like GitHub Actions, GitLab CI, Jenkins, or CircleCI. Whenever code changes are pushed or pull requests are created, the CI system will automatically perform schema checks and report any issues before the code is merged and deployed.
- Monitor and review schema changes: configure the schema check tool to generate reports, logs, or notifications when breaking changes are detected. This enables your team to review the changes and decide on the best course of action, such as fixing the issue, updating client applications to handle the change, or reverting the change entirely.
Let's consider a scenario where you have an existing GraphQL schema for an e-commerce application, and a developer wants to make changes to the User type. Here's the initial schema:
type User {
id: ID!
name: String
age: String
email: String
}
The developer decides to change the age field from a String to an Int. They update the schema as follows:
type User {
id: ID!
name: String
age: Int # type used to be String
email: String
}
Inigo will alert you to any clients that are still using age as a String.
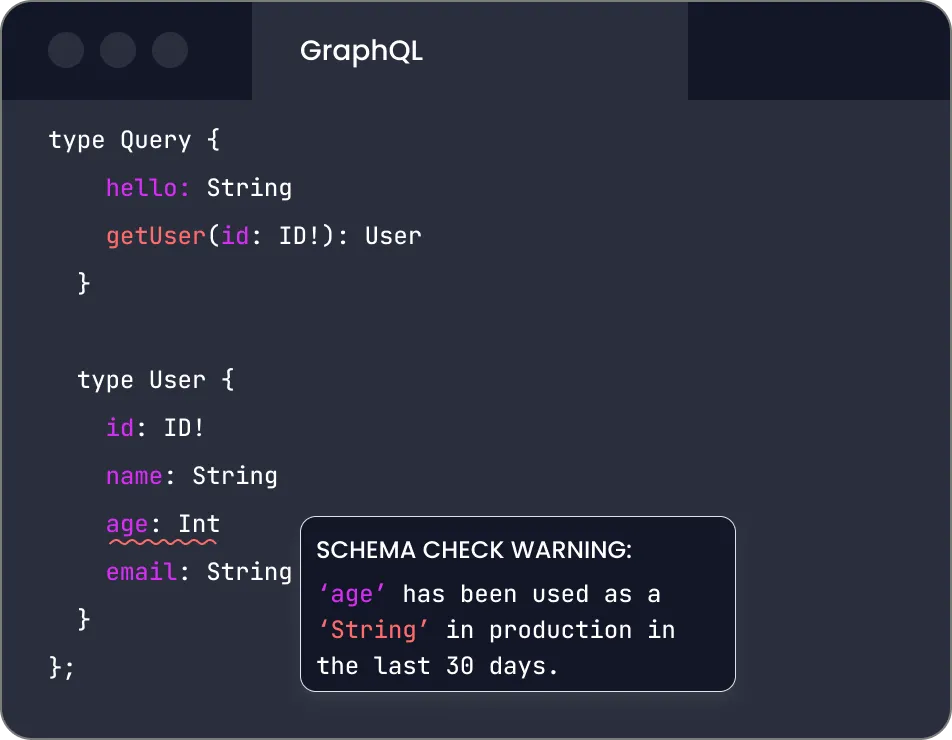
Subgraph visibility for different teams
In GraphQL, subgraph visibility refers to the ability to control access to specific parts of a schema, such as types or fields, based on the client or user's permissions. Managing subgraph visibility is crucial for maintaining data security and privacy in a GraphQL API, as it helps prevent unauthorized access to sensitive data or internal implementation details. To implement subgraph visibility, developers can use a combination of schema directives and custom middleware, such as GraphQL Shield or custom resolvers, to conditionally expose or hide certain parts of the schema based on the client's authorization levels (typically controlled by a security orchestration product). With Inigo, subgraph visibility is built in.
Finding performance issues
Identifying resource-heavy and/or unused objects in schemas
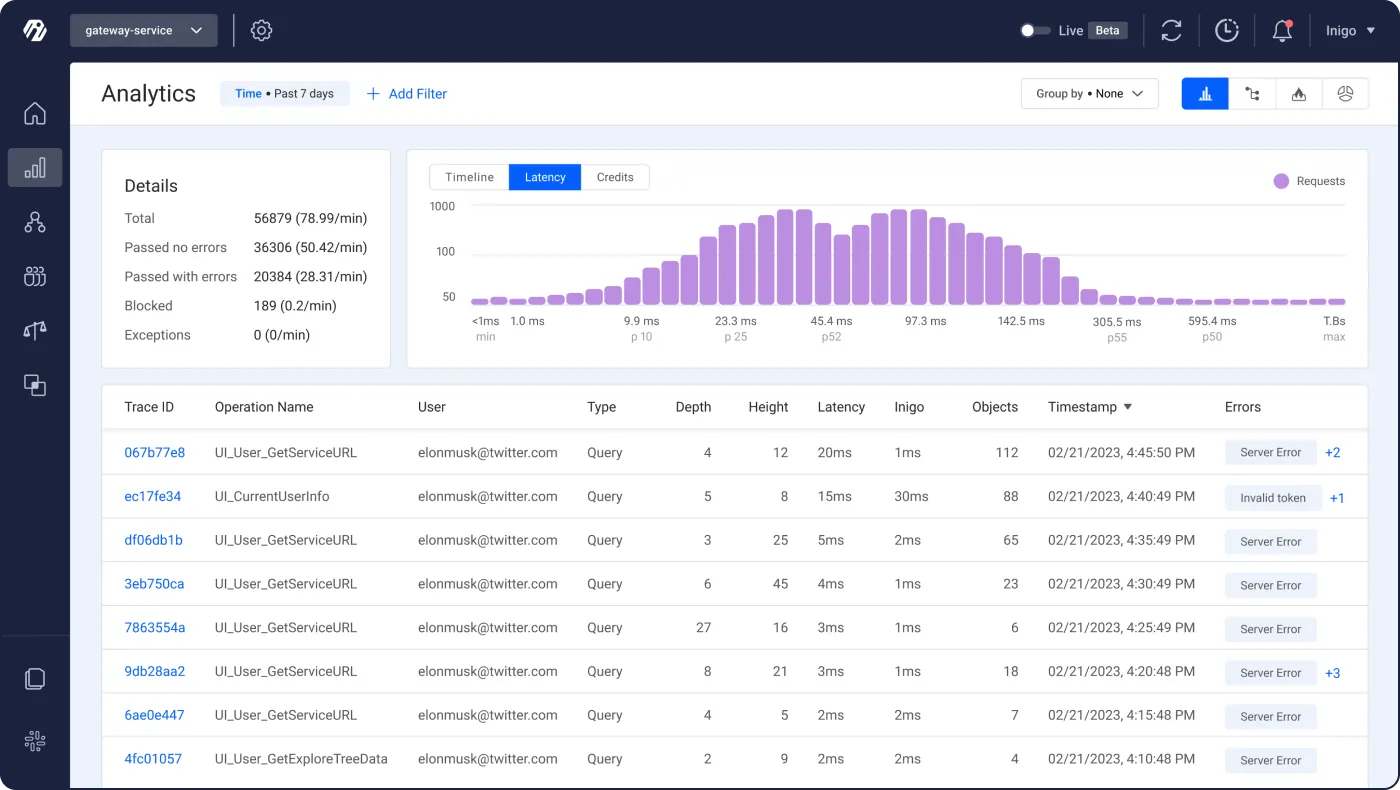
In GraphQL, identifying resource-heavy queries and types is crucial for optimizing performance and minimizing unnecessary data retrieval. Similarly, identifying unused objects is also important, as it can result in unnecessary costs for data sources in terms of lookup and computation. Identifying these “long-tail” objects typically involves:
- Query logging: Set up logging for your GraphQL server to capture information about incoming queries, including execution time, response size, and any errors. This data will help you identify slow-performing or resource-intensive queries.
- Query complexity analysis: Calculate the complexity of each query. A high complexity score may indicate that a query is resource-intensive and may need optimization.
- Monitoring server metrics: Keep an eye on server metrics like CPU usage, memory consumption, and response time. Spikes in these metrics could signal that certain queries or types are putting excessive strain on your server.
- Field usage tracking: Identify which fields are frequently requested and which are rarely used.
Conclusion
The growing adoption of GraphQL in production environments highlights the importance of integrating it seamlessly into the development pipeline. As organizations face new challenges, such as schema planning, schema optimization, query monitoring, and error handling, Inigo provides a valuable solution to what would otherwise be unscalable and costly development cycles. Rather than functioning as a GraphQL server, Inigo offers a comprehensive suite of tools designed to contextualize GraphQL traffic, deliver granular query-level analytics, and ensure that dev teams have all the information they need to maintain a clean and efficient schema.