Product
Solutions


GraphQL Error Handling

Overview
For those coming from the world of REST/HTTPs APIs, GraphQL’s error handling paradigm can feel undisciplined and inconsistent. Unlike in REST/HTTP APIs, where error handling is based on status codes returned by the API, GraphQL request are always made using the same /graphql url and always return a 200 OK response. Instead of being signalled via status codes, errors reside inside the response payload, alongside any data returned.
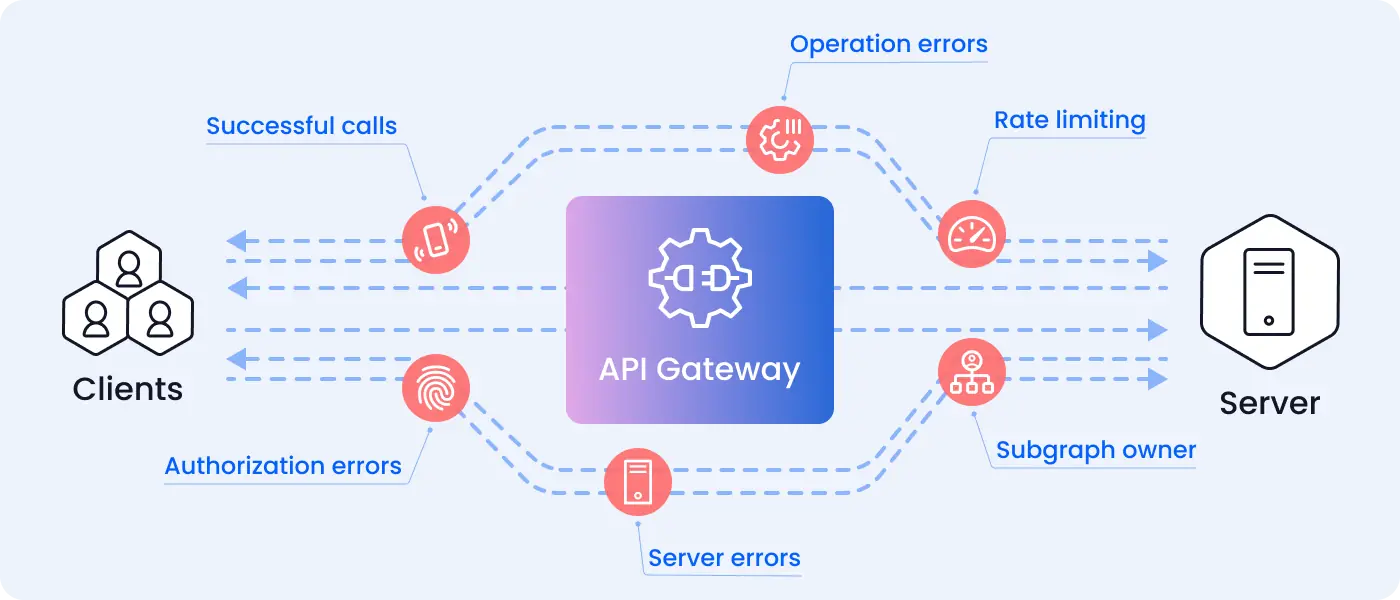
This makes GraphQL error handling a blind spot for most engineers and security teams. Standard WAFs will generally only look at HTTP headers; thus with GraphQL they are unable to contextualize and differentiate between:
- Successful calls
- Server errors
- Rate limiting
- Operation errors
- Authorization errors
- Subgraph owner
Additionally, there is little visibility when mission-critical objects and mutations, like purchase orders, fail. In this blog post, we cover some of the top problems with GraphQL’s default error handling, some best practice solutions, and how Inigo can help elevate GraphQL errors so they are quickly handled by the proper team.
Error Handling in GraphQL
GraphQL is transport agnostic, which means that it does not rely on the underlying transport mechanism used to transmit data between the client and the server. GraphQL APIs can use Web Sockets instead of HTTP for client-server communication if it suits the use case. As a result, GraphQL APIs do not rely on HTTP methods like GET, PUT, and POST, nor are HTTP status codes relevant.
In GraphQL, errors are returned as part of the server responses from the server. When an error occurs, the server returns a response with an errors field that contains information about the error. Clients can determine whether the GraphQL request was successful or not by looking at this errors field.
Example 1:
Here is an example of a GraphQL response with an error:
{
"data": {
"createUser": null
},
"errors": [
{
"message": "Email already in use",
"locations": [
{
"line": 2,
"column": 3
}
],
"path": [
"createUser"
]
}
]
}
In the above example, the errors field in the response is an array of errors. Each error contains three fields:
- Message: Provides a description of the error
- Location: Indicates where in the query the error occurred
- Path: Indicates which field in the query caused the error
In this case, the error message "Email already in use" indicates that the email address specified in the createUser mutation is already in use by another user.
In addition to the above three fields, there is an extensions field that can be used to add extra information about the error.
Example 2:
The following mutation should result in the creation of a user:
mutation {
createUser(name: "XYZ", email: "[email protected]") {
name,
email,
password
}
}
The mutation results in the following response:
{ "errors": [ {
"message": "Cannot query field \"password\" on type \"User\".",
"locations": [ { "line": 5, "column": 6 } ],
"extensions": {
"code": "GRAPHQL_VALIDATION_FAILED",
"stacktrace": [
"GraphQLError: Cannot query field \"password\" on type \"User\".", " at Object.Field (/my_project/node_modules/graphql/validation/rules/FieldsOnCorrectTypeRule.js:48:31)", " ...additional lines..."
]
}
} ] }
Note that the path element is missing from the error object because, unlike the error in Example 1, this error is raised before execution. These are commonly referred to as request errors, and they include parsing and validation failures. Since this mutation was run on an Apollo server, the error extensions are specific to Apollo’s implementation. These may be different when using other GraphQL implementations.
Problems with GraphQL's Error Handling
As you can see, GraphQL's error-handling mechanism is substantially different from how we are accustomed to dealing with errors. As a result, GraphQL error handling presents several challenges:
Difficult to parse
A GraphQL response may contain both data and errors. The presence of errors does not imply the absence of data. In the absence of errors, the errors key is absent from the response.
In the following snippet, for example, if you merely parse the errors key and assume the entire response is erroneous, you will miss out on the partial data returned.
{
"data": {
"user": {
"name": "Inspector Spacetime",
"userFriends": [{
"id": 1,
"name": "Constable Reggie"
}, {
"id": 2,
"name": null
}]
}
},
"errors": [{
"message": "Could not fetch name of friend "
"locations": [{
"line": 2,
"column": 5
}],
"path": [
"user", "userFriends", 1, "name"
]
}]
}
No standard format
Different GraphQL implementations might report errors in different formats, or utilize different error-handling conventions, making it difficult for a standard API gateway to parse.
The following is an erroneous response for failed validation in Hasura:
{
"errors": [{
"extensions": {
"path": "$.selectionSet.users.selectionSet.name",
"code": "validation-failed"
},
"message": "field \"name\" not found in type: 'users'"
}]
}
The following is an erroneous response for failed validation in Apollo:
{
"errors": [{
"message": "Cannot query field \"name\" on type \"User\".",
"locations": [{
"line": 2,
"column": 3
}],
"extensions": {
"code": "GRAPHQL_VALIDATION_FAILED",
"exception": {
"stacktrace": [
"GraphQLError: Cannot query field \"name\" on type \"User\".", "...additional lines..."
]}
}
}],
"data": null
}
It's always a good idea to consult the documentation for the specific implementation you are using for more information on error handling.
Hard to differentiate
A GraphQL response may be the result of many requests to distinct data sources. Certain fields may fail due to a lack of authorization, while others may fail due to faulty validation, and we may only obtain a partial response for the remainder. The errors list might contain a wide range of errors, making it difficult for the client to handle and respond.
Here's an example of multiple errors being returned in response to a query:
{
"errors": [
{
"message": "The provided argument value '9999999999' is invalid for the input argument 'id' on field 'node' of type 'ID'.",
"locations": [
{
"line": 2,
"column": 3
}
],
"path": [
"query",
"node"
],
"extensions": {
"code": "GRAPHQL_VALIDATION_FAILED",
"field": "id"
}
},
{
"message": "Access Denied",
"locations": [
{
"line": 6,
"column": 3
}
],
"path": [
"query",
"customerAccessTokenCreate"
],
"extensions": {
"code": "ACCESS_DENIED"
}
}
]
}
In this example, the HTTP status code is 200 OK, but the response body includes two error objects in the errors key. The first error object indicates that the provided value for the "id" argument on the "node" field is invalid. The second error object indicates that access was denied when attempting to create a customer access token.
No prioritization of business-critical errors
This last example demonstrates how multiple errors might be returned in a GraphQL response. In addition to being difficult to distinguish, multiple errors are also difficult to prioritize.
In some cases, a data not found error may be for a single item in the list, which may not affect the client and would be safe to disregard. In another scenario, even if partial data is received, it might make sense to regard the full response as erroneous. Prioritizing distinct error types and creating a hierarchy is therefore difficult to accomplish with GraphQL. It is also important to be able to distinguish and prioritize handling of business-critical errors, for instance, those involving payments.
Disclosure of sensitive information
Field recommendations in the error message may reveal sensitive information or expose unexpected functionality that is not intended to be utilized by clients, such as fields that allow clients to manipulate resources or execute arbitrary code. This information might then be used in “fuzzing” attacks executed on the server.
The following is a query that requests product categories:
query {
searchCategories {
name
description
}
}
The server returns the following response:
{
"errors": [
{
"message": "Cannot query field \"searchCategories\" on type \"Query\". Did you mean \"searchUsers\" or \"searchRoles\"?",
"locations": [{
"line": 144,
"column": 3
}]
}
]
}
The response reveals functionality and exposes sensitive information to the client, thus putting the application (and data) at risk.
Hard to debug errors in subgraphs
A federated GraphQL architecture refers to a way of organizing a GraphQL API as a network of independent GraphQL services that work together to provide a single, unified GraphQL API. Each of the independent GraphQL APIs are known as subgraphs. A router API is exposed to the client in such an architecture and GraphQL requests are routed by the router to the subgraph that can resolve the query or fields of the query.
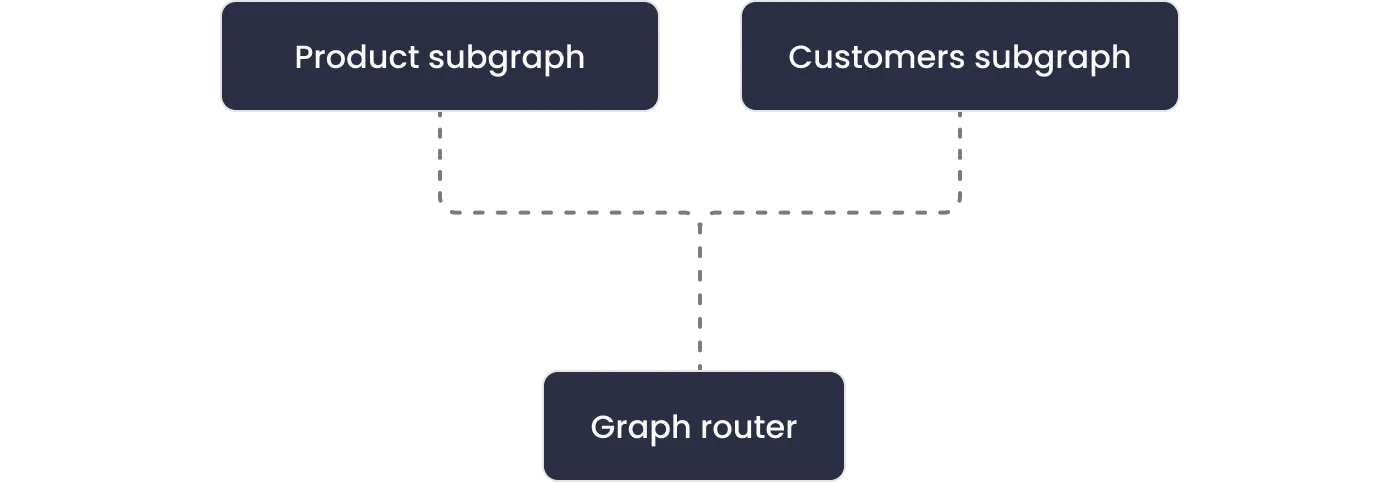
In the context of error handling, a federated GraphQL architecture can be confusing. Each service subgraph may return different error messages, making it more difficult to understand the overall context of the errors and their relationships to the original queries.
For example, let's say we have two subgraphs - customer subgraph and a product subgraph, and there is an error while querying a customerInfo field. The following is a snippet of the error received:
{
"errors": [
{
"message": "Internal server error",
"path": ["customerInfo"]
}
]
}
This error message provides very little information about what went wrong and why the user is unable to retrieve their customer information. In some cases, tracing an error like this in a subgraph can be very time-consuming and require a deep understanding of the underlying architecture.
Best Practices for Error Handling
Error handling and debugging may be difficult for GraphQL APIs, but there are industry-wide practices and approaches that can help us deal with them more effectively. Some of the solutions to the problems we discussed above are as follows:
Write custom error handling middleware
Since all errors in GraphQL result in a 200 status code, in order to provide “HTTP-readable” errors to the client, a developer might write custom error handling middleware that intercepts all errors before they are returned to the client. This middleware categorizes each error based on its type and then translates it into a readable error message.
The following is an example of custom error handler for a GraphQL server:
customErrorHandler = (err, req, res, next) => {
const error = formatError(err);
const { message, locations, path, extensions } = error;
let statusCode = 500;
let errorType = 'INTERNAL_SERVER_ERROR';
let errorMessage = 'Internal server error. Please try again later.';
if (extensions && extensions.exception) {
const { name } = extensions.exception;
if (name === 'ValidationError') {
statusCode = 400;
errorType = 'VALIDATION_ERROR';
errorMessage = 'Invalid input. Please provide valid data for the following fields:';
}
}
const response = {
errorType,
message: errorMessage,
locations,
path,
};
res.status(statusCode).json(response);
};
const app = express();
app.use('/graphql', graphqlHTTP({
schema,
rootValue,
customErrorHandler,
graphiql: true
}));
app.listen(4000, () => {
console.log('Running a GraphQL API server at localhost:4000/graphql');
});
This middleware intercepts GraphQL errors and categorizes them based on their name. In addition to categorization by name, you can also categorize them by:
- Error location: You can categorize errors based on where they occurred in the query or mutation. For example, you can categorize errors by the name of the field or argument that caused the error.
- Error severity: You can classify errors based on their severity level, such as critical errors that prevent the server from processing the request, or non-critical errors that don't affect the functionality of the application.
- Error source: You can categorize errors based on their source, such as server-side errors or client-side errors. This can help you identify whether the error was caused by your server, your client, or a third-party service.
- Error type: You can classify errors based on their type, such as validation errors, authorization errors, or input errors.
You can also write custom error handlers to hide native GraphQL error messages that should not be seen by the client. For example, error messages in GraphQL often contain field suggestions which might be exploited later:
{
"errors": [
{
"message": "Cannot query field \"hellooo\" on type \"Query\". Did you mean \"hello\"?",
"locations": [
{
"line": 33,
"column": 3
}
]
}
]
}
These sorts of error messages can be masked via a custom error formatting function as below:
const customFormatErrorFn = (error) => {
if (error.message.startsWith("Cannot query")) {
return {
message: "Invalid request"
};
}
return error
};
Treating errors as data
An alternative to the custom middleware approach is to use the “data as errors” approach. In the “data as errors” approach, error handling is baked into the GraphQL schema. You define different response types for when a response is successful and when it’s not. For example, say we are designing a GraphQL API for fetching books for a library catalog:
type Book {
id: Id!
title: String!
}
type NotFound
{
message: String!
}
type Overdue
{
message: String!
lateFee: Float
}
You can use a union type to represent all possibilities of the response:
union BookResult = Book | NotFound | Overdue
type Mutation {
bookResult(id: Id!): BookResult
}
A client may then query for books based on the different states returned by the book result:
{
bookResult(id: 1) {
__typename
... on Book {
id
title
}
... on NotFound {
message
}
... on Overdue {
message,
lateFee
}
}
By modeling the errors in the schema itself, you leave it to the client handle the ones that are important.
Disable debug mode in production
Dev Mode, supported in some GraphQL implementations but not all, provides a lot of helpful information for developers during the development and testing phase, such as detailed error messages and a comprehensive list of available fields and arguments. However, it is generally recommended to disable dev mode in production since it can expose sensitive information about your GraphQL API, such as the structure of your database, server configuration details, and API keys, to potential attackers.
Avoiding leakage of sensitive information through errors
It is recommended to limit the amount of information returned in error messages and include only the minimum amount of information necessary to identify the error and help developers debug it. You’d certainly want to avoid including sensitive information such as database queries, user information, or system configuration details.
Configuring proper alerts and triggers for mission-critical business errors
Several critical business errors, if not rectified, have the ability to completely derail the system. Purchase orders, for example, are mission-critical objects and mutations that cannot fail, and when they do, unless there is sufficient error escalation and alerting in place, these mistakes might be missed, delaying redressal. In such situations, it is crucial that an event is triggered to alert the team responsible immediately.
Improve traceability for subgraphs
It is best practice for each subgraph to log errors to a centralized logging system that aggregates logs from all the subgraphs. You can use log aggregation tools that provide error alerts and analysis to help you identify trends and patterns. It is also important to set up monitoring and have alerts configured to notify subgraph teams when an error occurs. It is critical to offer an internal key to the subgraph without disclosing too much information externally.
How Inigo can help
Companies are increasingly implementing GraphQL in their production environments. With this growth comes a new set of challenges, including how to secure GraphQL, analyze blind spots, and gain visibility into GraphQL traffic and errors. This is where Inigo comes in.
Inigo is not a GraphQL server. Instead, it offers a comprehensive set of tools to contextualize GraphQL traffic, provide granular query-level analytics, and elevate errors to the appropriate team.
For example, on the Inigo dashboard, you’re able to see all of the queries and errors coming into and going out of your GraphQL setup. These errors are likely returning a 200 status code, which means that if you're using a standard API gateway, you have little visibility into them.
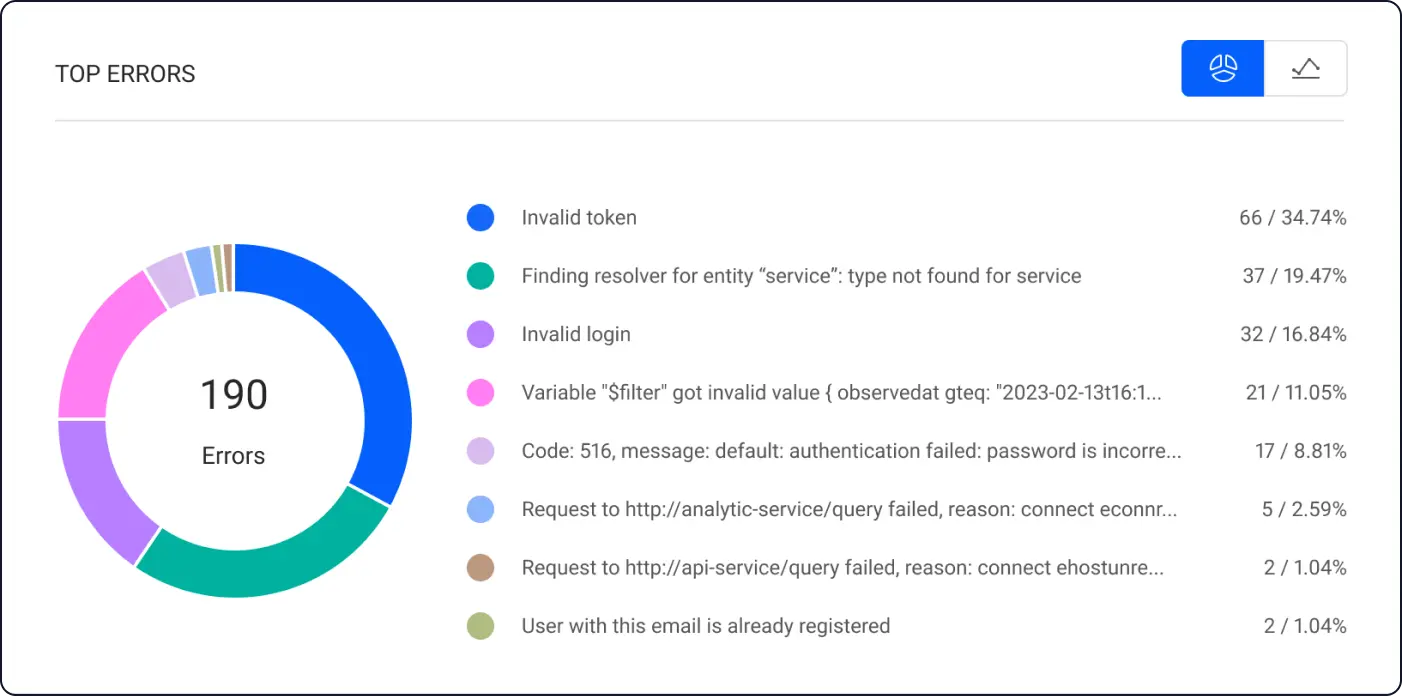
You’re also able to filter queries based on whether they responded with an error:
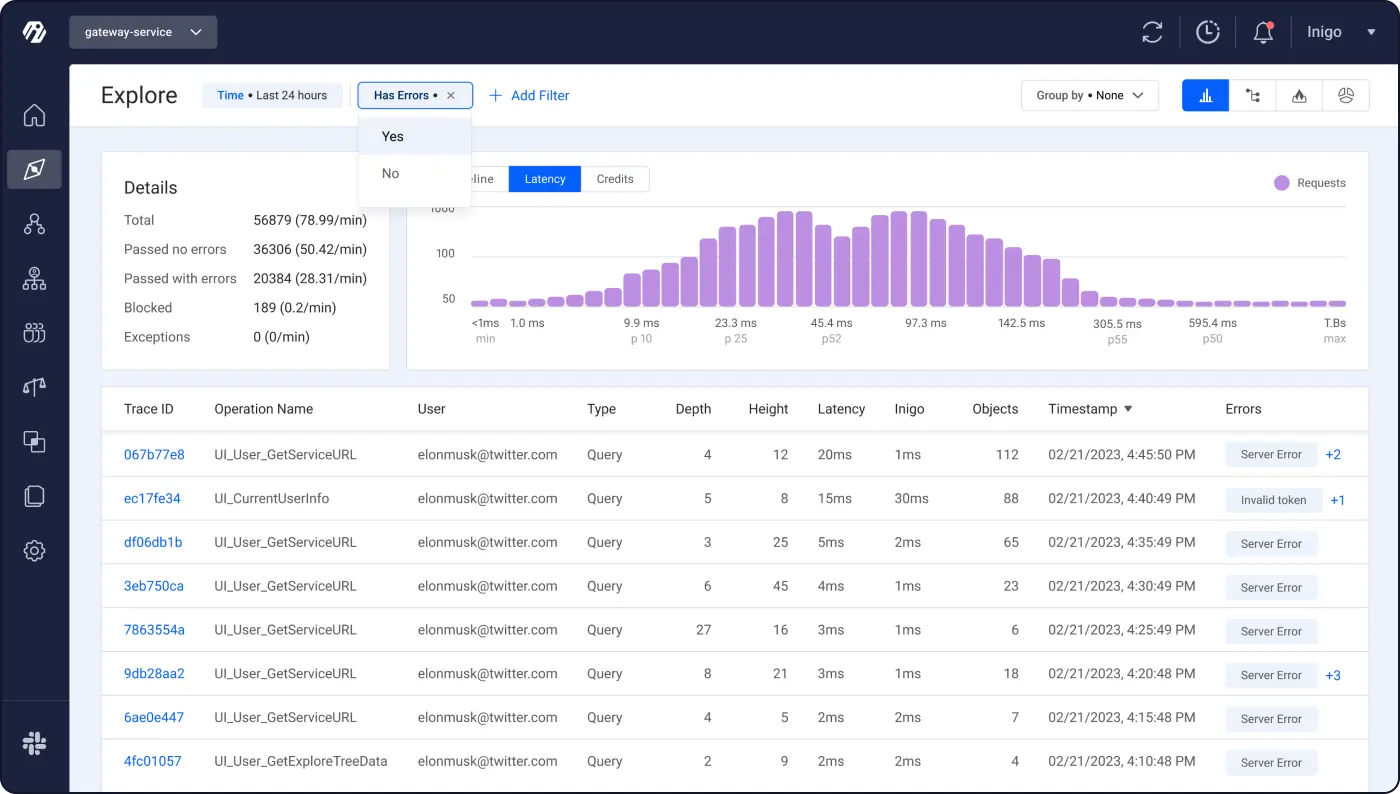
These errors are categorized/labeled, and you can dig into them:
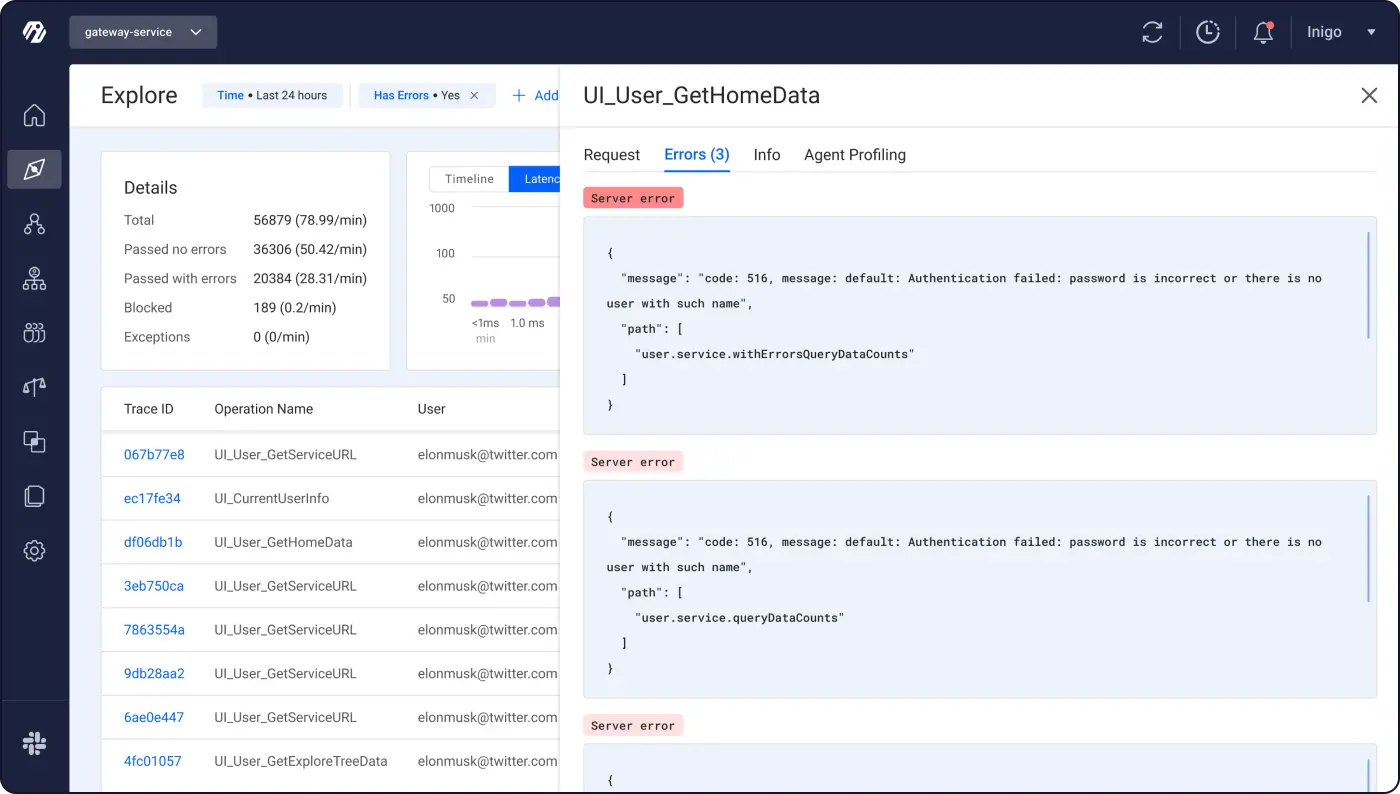
Additionally, Inigo makes it easier to implement GraphQL error handling best practices, for example, by blocking errors that contain PII, or by allowing users to automatically configure alerts that will escalate business-critical errors to responsible parties via Slack or email.
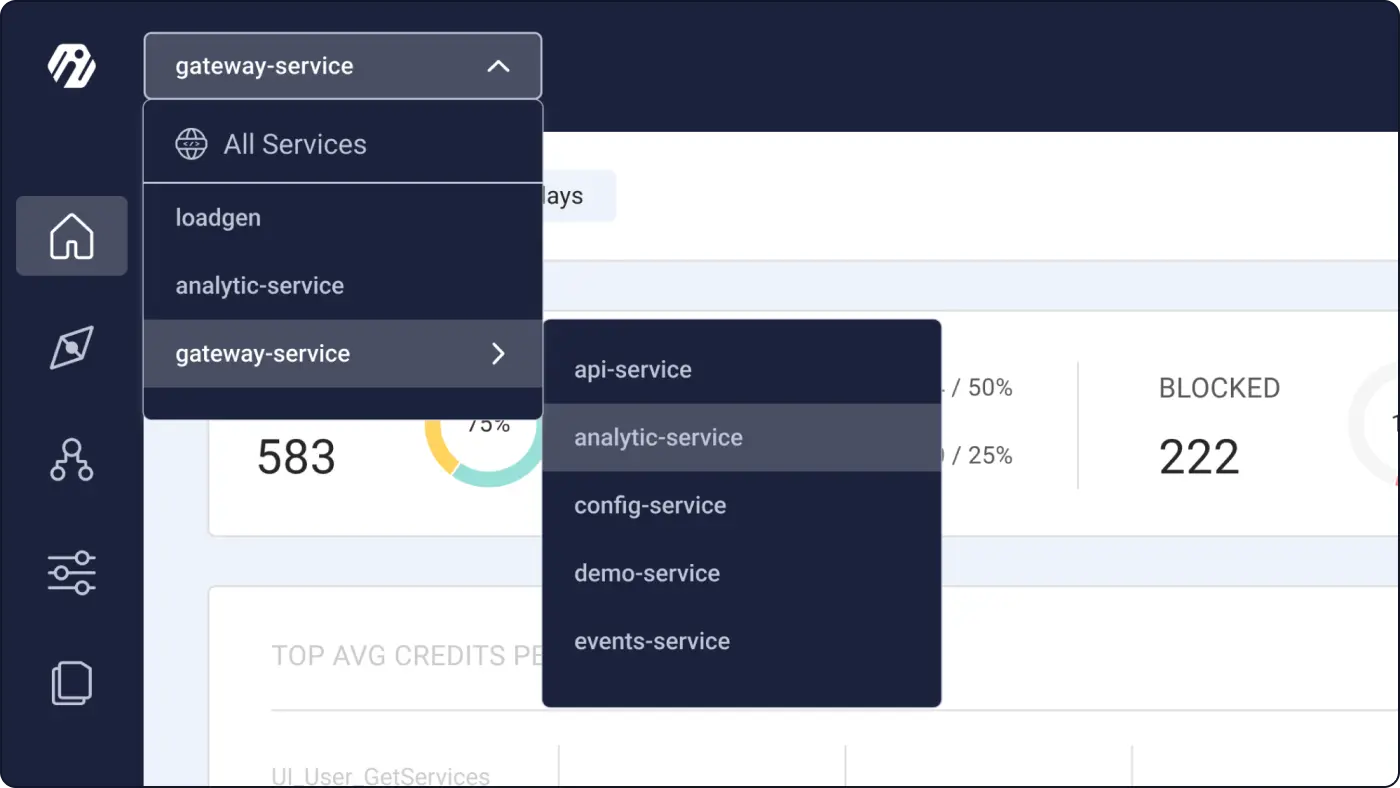
Finally, in the case of multiple errors, Inigo provides subgraph visibility. In a federated GraphQL system, when you get an error, you might not know which subgraph that error comes from. With Inigo, you can dive into specific subgraphs to explore the errors:
Conclusion
Error handling is a key component of API development. For GraphQL APIs in particular, error handling requires careful thinking and design. You can learn more on why defending GraphQL APIs is challenging for security engineers here. In conclusion, it is critical to have a contextualized way to surface GraphQL analytics and elevate alerts to improve the overall stability and usefulness of your GraphQL API.