Product
Solutions


Subgraph Visibility in GraphQL
Introduction
The appeal of creating a GraphQL API often lies in its ability to expose a single data graph, which can sit atop multiple data sources, such as REST APIs and SQL databases. This structure allows data to be queried in a way that truly reflects the relationships between the nodes in the graph.
However, as more objects and their relationships are exposed through various types and fields, the graph can quickly become unwieldy. A moderately complex application can rapidly require a vast array of type definitions, making it challenging for multiple people or teams to collaborate on building the API. Additionally, the GraphQL API can become a single vulnerable point of failure in the system.
The solution? A distributed GraphQL architecture. By breaking up the schema into smaller services for development purposes and then recombining each independently managed portion into a Gateway API, client applications can remain oblivious to these divisions when querying data. This approach is particularly valuable for larger, complex applications that necessitate a single, comprehensive API.
Today, a distributed GraphQL architecture is typically referred to as federated GraphQL and implemented via a tool called Apollo Federation. Federated GraphQL has helped companies like Netflix and PayPal scale their GraphQL APIs.
Challenges of federated GraphQL

While a federated GraphQL schema offers many benefits, including improved developer productivity and the ability to create a more coherent API across multiple teams, it also introduces a few challenges, including:
-
Schema Coordination: In a federated architecture, different teams can make updates to their part of the schema independently. This requires careful coordination to ensure that changes made by one team don't break another team's queries. Tools like schema registries and schema validation tools can help with this.
-
Performance: The process of splitting a GraphQL schema across multiple services and aggregating the results can add additional latency to the request. The gateway must sometimes make multiple round-trip requests to different services to resolve a single query, which can impact performance.
-
Error Handling: Errors can be more challenging to trace in a federated environment. Errors from different subgraphs can become entangled, complicating the debugging process. For instance, a single query could trigger errors in multiple subgraphs, making it hard to isolate and resolve each one. This issue becomes even more severe as the number of subgraphs increases.
-
Security and Authorization: Each service in a federated architecture represents a potential point of attack. Ensuring consistent security practices across all services, including data privacy and access controls, is critical.
-
Testing and Debugging: Testing in a federated environment can be more complex than in a monolithic one. Testing a change might require setting up a more complicated testing environment that includes the gateway and all the necessary services.
-
Consistency: Ensuring a consistent approach across multiple services can be challenging. For instance, different teams might have different naming conventions or different ways of designing their part of the schema.
-
Resource Allocation: Conversations about resource allocation - how much memory, CPU, and bandwidth should each subgraph receive - can be difficult without the right tools and data.
Despite these challenges, many organizations find that the benefits of a federated GraphQL architecture outweigh the drawbacks. The key to a successful implementation lies in careful planning, good communication among teams, and the use of appropriate tooling.
The need for subgraph visibility
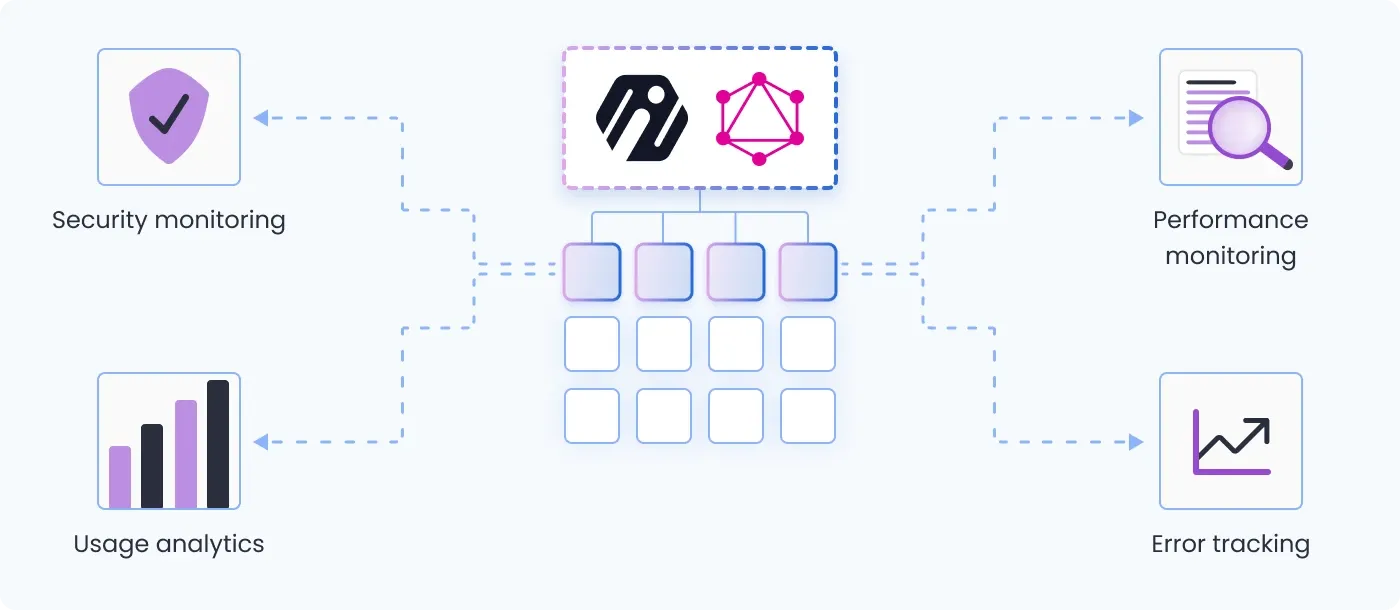
Subgraph visibility in the context of a federated GraphQL architecture refers to the ability to observe and understand the individual GraphQL services that make up the federated data graph. This includes things like:
-
Performance monitoring: It's important to monitor metrics like response times, error rates, and throughput for each subgraph. This allows teams to identify performance bottlenecks and optimize the subgraphs accordingly.
-
Usage analytics: Understanding how each subgraph is being used—which fields and types are queried most frequently—helps teams make better decisions about schema design and resource allocation.
-
Error tracking: Having visibility into errors at the subgraph level simplifies debugging and troubleshooting. Teams can trace errors back to the source subgraph and subgraph owners have the necessary context to resolve issues.
-
Security monitoring: Monitoring security-related metrics for each subgraph, like authentication failures or abnormal usage spikes, helps identify potential vulnerabilities or attacks early on.
Subgraph visibility is important because it allows for more effective monitoring, troubleshooting, and optimization of a federated GraphQL API. By improving subgraph visibility, teams can ensure that their federated GraphQL architecture is performant, reliable, and secure.
Inigo: A Solution to Enhance Subgraph Visibility
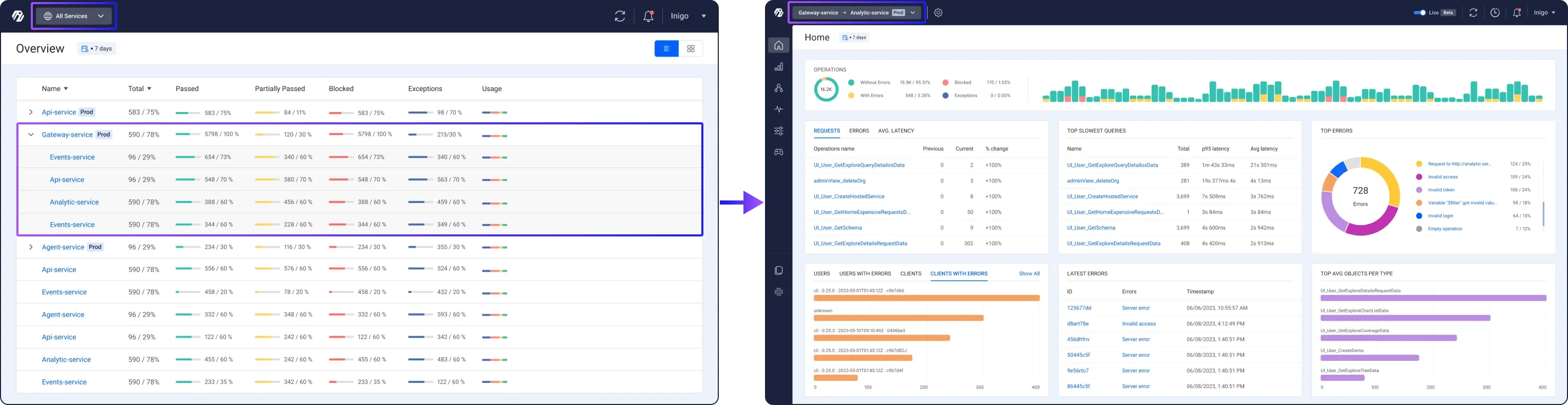
Inigo is a GraphQL monitoring and analytics platform that provides in-depth visibility into subgraphs in a federated GraphQL architecture. Some of the features that improve subgraph visibility include:
- Performance dashboards for each subgraph display metrics like response time, error rate, and throughput. This helps teams quickly identify issues and areas for optimization.
- Usage analytics showing the most frequently queried types, fields, and connections within each subgraph. This data aids in improving schema design and determining how to allocate resources.
- Advanced error tracking that groups errors by subgraph, making them easier to debug. Subgraph owners have the context to resolve issues efficiently.
- Automated security monitoring that detects anomalies like spikes in authentication failures or unusual traffic volumes at the subgraph level. Teams get alerts about potential vulnerabilities early.
- Resource allocation recommendations based on usage data. Inigo can suggest ways to optimize how resources like CPU, memory, and bandwidth should be distributed across subgraphs according to demand.
By providing targeted visibility and insights into each subgraph, Inigo enables federated GraphQL teams to build, monitor, and optimize their API more effectively. Issues that would otherwise be difficult to troubleshoot or anticipate become much more manageable.
Conclusion
Subgraph visibility is essential for successfully operating a federated GraphQL API at scale. Without insight into how each subgraph is functioning, issues are nearly impossible to trace and resolve. Inigo is a purpose-built tool for enhancing visibility across federated graphs and overcoming the challenges associated with distributed architectures.
Try Inigo today to gain transparency into your federated graph. Learn more and get started with a free trial at app.inigo.io.